
NVIDIA Blackwell’s scale-up capabilities set the stage to scale out the world’s largest AI factories.
The NVIDIA Blackwell structure is the reigning chief of the AI revolution.
Many consider Blackwell as a chip, however it might be higher to consider it as a platform powering large-scale AI infrastructure.
Surging Demand and Mannequin Complexity
Blackwell is the core of a whole system structure designed particularly to energy AI factories that produce intelligence utilizing the biggest and most complicated AI fashions.
At the moment’s frontier AI fashions have lots of of billions of parameters and are estimated to serve practically a billion customers per week. The following era of fashions are anticipated to have properly over a trillion parameters — and are being skilled on tens of trillions of tokens of information drawn from textual content, picture and video datasets.
Scaling out an information heart — harnessing as much as hundreds of computer systems to share the work — is critical to fulfill this demand. However far larger efficiency and vitality effectivity can come from first scaling up: by making an even bigger laptop.
Blackwell redefines the bounds of simply how huge we will go.
Exponential progress of parameters in notable AI fashions over time.
Knowledge Supply: Epoch (2025), with main processing by Our World In Knowledge
At the moment’s Most Difficult Type of Computing
AI factories are the machines of the following industrial revolution. Their work is AI inference — probably the most difficult type of computing identified at the moment — and their product is intelligence.
These factories require infrastructure that may adapt, scale out and maximize each little bit of compute useful resource out there.
What does that seem like?
A symphony of compute, networking, storage, energy and cooling — with integration on the silicon and methods ranges, up and down racks — orchestrated by software program that sees tens of hundreds of Blackwell GPUs as one.
The brand new unit of the info heart is NVIDIA GB200 NVL72a rack-scale system that acts as a single, huge GPU.

NVIDIA CEO Jensen Huang reveals off the NVIDIA GB200 NVL72 system and the NVIDIA Grace Blackwell superchip throughout his keynote at CES 2025.
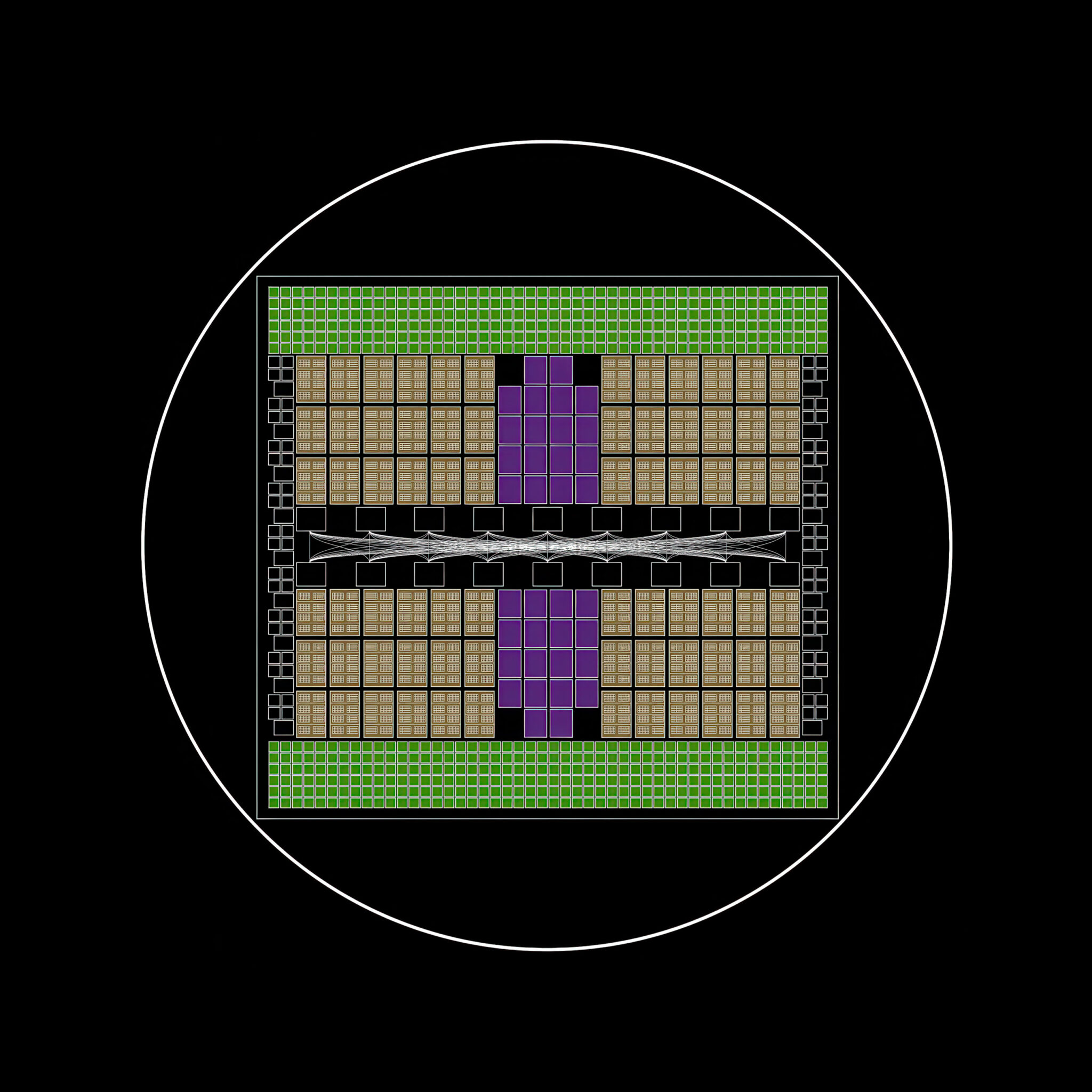
Start of a Superchip
On the core, the NVIDIA Grace Blackwell superchip unites two Blackwell GPUs with one NVIDIA Grace CPU.
Fusing them right into a unified compute module — a superchip — boosts efficiency by an order of magnitude. To take action requires a brand new high-speed interconnect expertise launched with the NVIDIA Hopper structure: NVIDIA NVLink chip-to-chip.
This expertise unlocks seamless communication between the CPU and GPUs, enabling them to share reminiscence immediately, leading to decrease latency and better throughput for AI workloads.


It takes a symphony of creation, chopping, meeting and inspection to construct a superchip.
A New Interconnect for the Superchip Period
Scaling this efficiency throughout a number of superchips with out bottlenecks was unimaginable with earlier networking expertise. So NVIDIA created a brand new sort of interconnect to maintain efficiency bottlenecks from rising and allow AI at scale.

A Spine That Clears Bottlenecks
The NVIDIA NVLink Swap backbone anchors GB200 NVL72 with a exactly engineered net of over 5,000 high-performance copper cables, connecting 72 GPUs throughout 18 compute trays to maneuver knowledge at a staggering 130 TB/s.
That’s quick sufficient to switch the whole web’s peak site visitors in lower than a second.

Two miles of copper wire is exactly lower, measured, assembled and examined to create the blisteringly quick NVIDIA NVLink Swap backbone.

The backbone cartridge is inspected earlier than set up.
The backbone, powered up, can transfer a whole web’s value of information in lower than a second.
Constructing One Large GPU for Inference
The combination of all this superior {hardware} and software program, compute and networking allows GB200 NVL72 methods to unlock new potentialities for AI at scale.
Every rack weighs one-and-a-half tons — that includes greater than 600,000 components, two miles of wire and hundreds of thousands of traces of code converged.
It acts as one large digital GPU, making factory-scale AI inference potential, the place each nanosecond and watt issues.


GB200 NVL72 In every single place
NVIDIA then deconstructed GB200 NVL72 in order that companions and clients can configure and construct their very own NVL72 methods.
Every NVL72 system is a two-ton, 1.2-million-part supercomputer. NVL72 methods are manufactured throughout greater than 150 factories worldwide with 200 expertise companions.

From cloud giants to system builders, companions worldwide are producing NVIDIA Blackwell NVL72 methods.
Time to Scale Out
Tens of hundreds of Blackwell NVL72 methods converge to create AI factories.
Working collectively isn’t sufficient. They have to work as one.
NVIDIA Spectrum-X Ethernet and Quantum-X800 InfiniBand switches make this unified effort potential on the knowledge heart stage.
Every GPU in an NVL72 system is linked on to the manufacturing facility’s knowledge community, and to each different GPU within the system. GB200 NVL72 methods supply 400 Gbps of Ethernet or InfiniBand interconnect utilizing NVIDIA ConnectX-7 NICs.

NVIDIA Quantum-X800 Swap, NVLink Swap, and Spectrum-X Ethernet unify one or many NVL72 methods to perform as one.


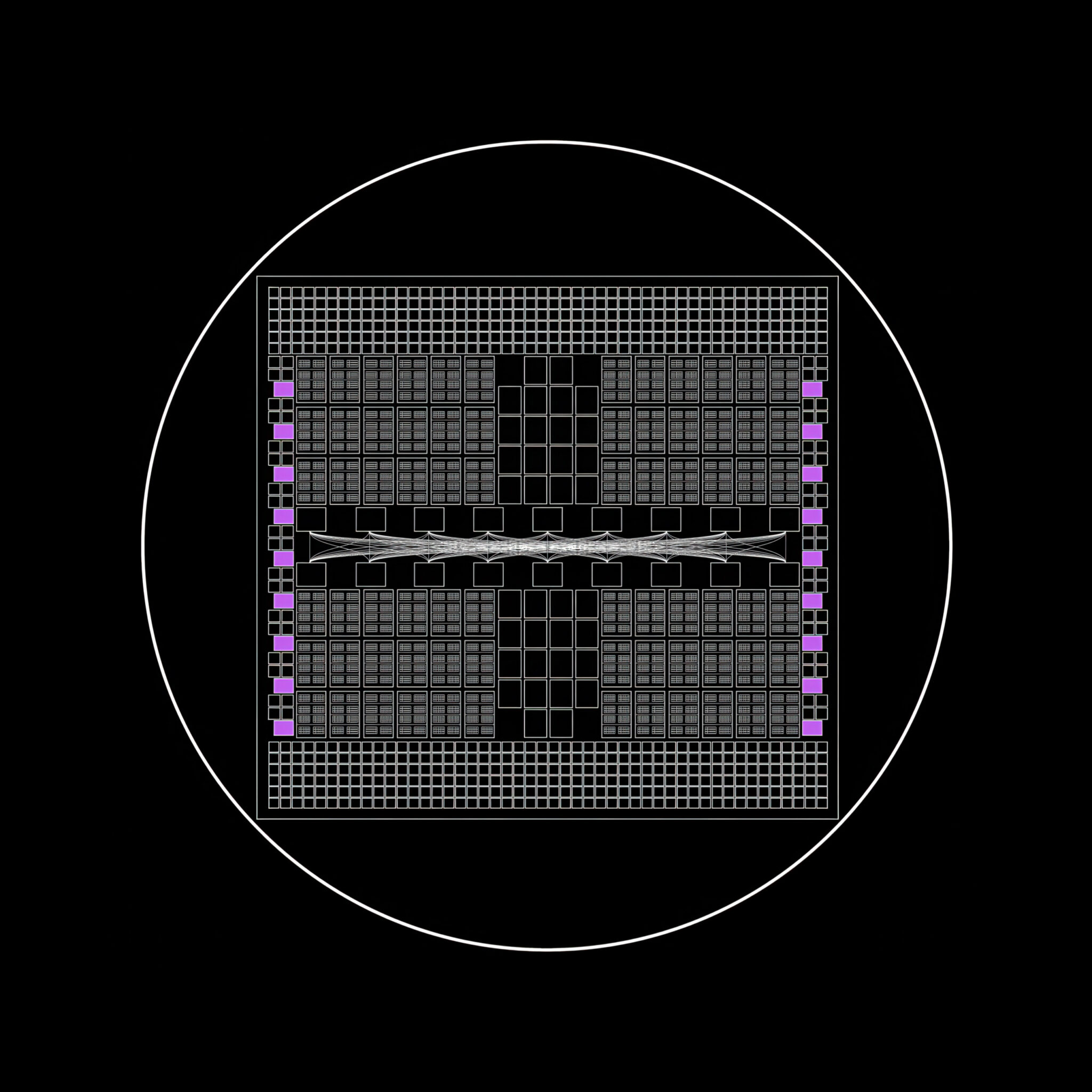
Opening Traces of Communication
Scaling out AI factories requires many instruments, every in service of 1 factor: unrestricted, parallel communication for each AI workload within the manufacturing facility.
NVIDIA BlueField-3 DPUs do their half to spice up AI efficiency by offloading and accelerating the non-AI duties that hold the manufacturing facility operating: the symphony of networking, storage and safety.

NVIDIA GB200 NVL72 powers an AI manufacturing facility by CoreWeave, an NVIDIA Cloud Associate.

The AI Manufacturing facility Working System
The info heart is now the pc. NVIDIA Dynamo is its working system.
Dynamo orchestrates and coordinates AI inference requests throughout a big fleet of GPUs to make sure that AI factories run on the lowest potential price to maximise productiveness and income.
It may possibly add, take away and shift GPUs throughout workloads in response to surges in buyer use, and route queries to the GPUs greatest match for the job.

Colossus, xAI’s AI supercomputer. Created in 122 days, it homes over 200,000 NVIDIA GPUs — an instance of a full-stack, scale-out structure.
Blackwell is greater than a chip. It’s the engine of AI factories.
The world’s largest-planned computing clusters are being constructed on the Blackwell and Blackwell Extremely architectures — with roughly 1,000 racks of NVIDIA GB300 methods produced every week.
Associated Information

The UK’s ‘Goldilocks Second for AI’: NVIDIA, UK and US Leaders Spotlight AI Infrastructure Investments

The AI Makers: NVIDIA Companions in UK Advance Bodily and Agentic AI, Robotics, Life Sciences and Extra

NVIDIA Blackwell Extremely Units the Bar in New MLPerf Inference Benchmark

{kind=link}
Now Dwell: Europe’s First Exascale Supercomputer, JUPITER, Accelerates Local weather Analysis, Neuroscience, Quantum Simulation

Drift Car Air Freshener - The Original Wood Air Freshener - Car Odor Eliminator - Long Lasting Scent - Auto Accessories - Metal Clip - Essential Oils - Clean Ingredients - Teak Scent Starter Kit
$12.95 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AUTOBOO 26" and 16" Windshield Wipers Blades (Pack Of 2),OEM Quality Premium All-Seasons Wiper blades,Stable and Quiet Armor wiper blades
$16.99 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AstroAI L7 Tire Inflator Portable Air Compressor Cordless Mini Bike Pump with Digital Dual Values Display, 150 PSI Car Tires Air Pump with LED Lights&Pressure Gauge for Auto, Motorcycles, Bikes, Balls
$19.99 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
All-Purpose Stainless Steel Shower Squeegee for Shower Glass Door with 2 Adhesive Hooks, Bathroom Cleaner Tool Household Window Mirror Squeegee , Cleaning Tile Wall, Car, 10 Inch Silver
$13.98 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Leather Honey Leather Conditioner, Since 1968. for All Leather Items Including Auto, Furniture, Shoes, Purses and Tack. Non-Toxic and Made in The USA / 8 Fl Oz (Pack of 1)
$19.99 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
BOSCH 22A22B ICON Beam Wiper Blades - Driver and Passenger Side - Set of 2 Blades (22A & 22B)
$40.00 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amooca Car Seat Headrest Hook 4 Pack Hanger Storage Organizer Universal for Handbag Purse Coat fit Universal Vehicle Car Black S Type
$6.99 (as of January 20, 2026 05:24 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)