
{kind=link}
Editor’s observe: This publish is a part of Assume SMARTa collection targeted on how main AI service suppliers, builders and enterprises can increase their inference efficiency and return on funding with the newest developments from NVIDIA’s full-stack inference platform.
NVIDIA Blackwell delivers the very best efficiency and effectivity, and lowest whole value of possession throughout each examined mannequin and use case within the latest unbiased SemiAnalysis InferenceMAX v1 benchmark.
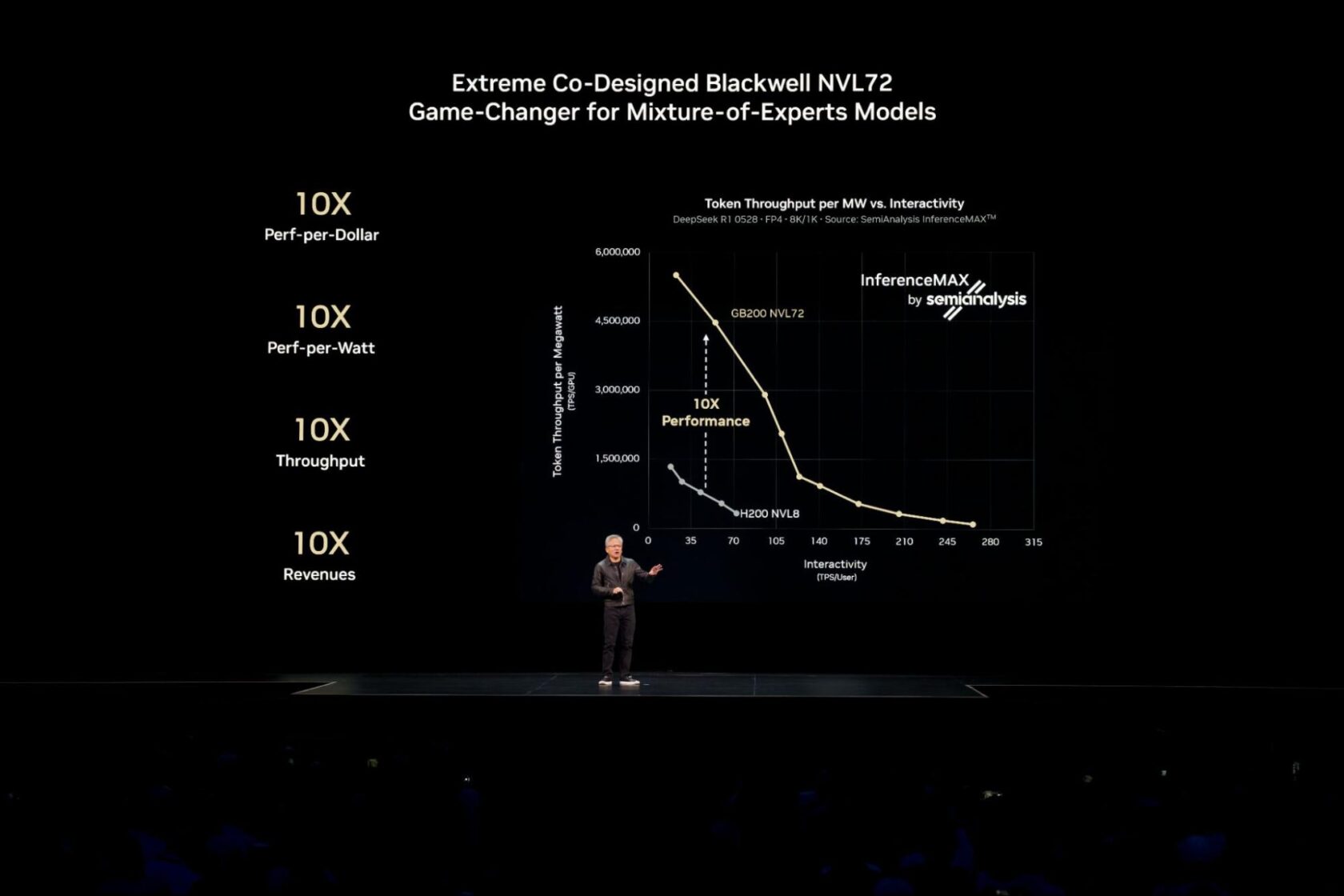
Reaching this industry-leading efficiency for right now’s most complicated AI fashionsreminiscent of large-scale mixture-of-experts (MoE) fashions, requires distributing (or disaggregating) inference throughout a number of servers (nodes) to serve thousands and thousands of concurrent customers and ship quicker responses.
The NVIDIA Dynamo software program platform unlocks these highly effective multi-node capabilities for manufacturing, enabling enterprises to realize this identical benchmark-winning efficiency and effectivity throughout their current cloud environments. Learn on to find out how the shift to multi-node inference is driving efficiency, in addition to how cloud platforms are placing this expertise to work.
Tapping Disaggregated Inference for Optimized Efficiency
For AI fashions that match on a single GPU or server, builders usually run many similar replicas of the mannequin in parallel throughout a number of nodes to ship excessive throughput. In a latest paperRuss Fellows, principal analyst at Signal65, confirmed that this strategy achieved an industry-first file combination throughput of 1.1 million tokens per second with 72 NVIDIA Blackwell Extremely GPUs.
When scaling AI fashions to serve many concurrent customers in actual time, or when managing demanding workloads with lengthy enter sequences, utilizing a way referred to as disaggregated serving unlocks additional efficiency and effectivity positive factors.
Serving AI fashions includes two phases: processing the enter immediate (prefill) and producing the output (decode). Historically, each phases run on the identical GPUs, which may create inefficiencies and useful resource bottlenecks.
Disaggregated serving solves this by intelligently distributing these duties to independently optimized GPUs. This strategy ensures that every a part of the workload runs with the optimization methods greatest fitted to it, maximizing general efficiency. For right now’s giant AI reasoning and MoE fashions, reminiscent of DeepSeek-R1, disaggregated serving is crucial.
NVIDIA Dynamo simply brings options like disaggregated serving to manufacturing scale throughout GPU clusters.
It’s already delivering worth.
The basset houndfor instance, used NVIDIA Dynamo to hurry up inference serving for long-context code era by 2x and improve throughput by 1.6x, all with out incremental {hardware} prices. Such software-driven efficiency boosts allow AI suppliers to considerably scale back the prices to fabricate intelligence.
Scaling Disaggregated Inference within the Cloud
Very like it did for large-scale AI coaching, Kubernetes — the {industry} normal for containerized utility administration — is well-positioned to scale disaggregated serving throughout dozens and even a whole lot of nodes for enterprise-scale AI deployments.
With NVIDIA Dynamo now built-in into managed Kubernetes providers from all main cloud suppliers, clients can scale multi-node inference throughout NVIDIA Blackwell methods, together with GB200 and GB300 NVL72with the efficiency, flexibility and reliability that enterprise AI deployments demand.
- Amazon Internet Providers is accelerating generative AI inference for its clients with NVIDIA Dynamo and built-in with Amazon EKS.
- Google Cloud is offering Dynamo recipe to optimize giant language mannequin (LLM) inference at enterprise scale on its AI Hypercomputer.
- Microsoft Azure is enabling multi-node LLM inference with NVIDIA Dynamo and ND GB200-v6 GPUs on Azure Kubernetes Service.
- Oracle Cloud Infrastructure (OCI) is enabling multi-node LLM inferencing with OCI Superclusters and NVIDIA Dynamo.
The push in direction of enabling large-scale, multi-node inference extends past hyperscalers.
I will notfor instance, is designing its cloud to serve inference workloads at scale, constructed on NVIDIA accelerated computing infrastructure and dealing with NVIDIA Dynamo as an ecosystem associate.
Simplifying Inference on Kubernetes With NVIDIA Grove in NVIDIA Dynamo
Disaggregated AI inference requires coordinating a workforce of specialised elements — prefill, decode, routing and extra — every with totally different wants. The problem for Kubernetes is now not about working extra parallel copies of a mannequin, however slightly about masterfully conducting these distinct elements as one cohesive, high-performance system.
NVIDIA Grovean utility programming interface now obtainable inside NVIDIA Dynamo, permits customers to offer a single, high-level specification that describes their total inference system.
For instance, in that single specification, a person may merely declare their necessities: “I would like three GPU nodes for prefill and 6 GPU nodes for decode, and I require all nodes for a single mannequin reproduction to be positioned on the identical high-speed interconnect for the quickest potential response.”
From that specification, Grove mechanically handles all of the intricate coordination: scaling associated elements collectively whereas sustaining right ratios and dependencies, beginning them in the appropriate order and inserting them strategically throughout the cluster for quick, environment friendly communication. Be taught extra about how one can get began with NVIDIA Grove on this technical deep dive.
As AI inference turns into more and more distributed, the mixture of Kubernetes and NVIDIA Dynamo with NVIDIA Grove simplifies how builders construct and scale clever functions.
Strive NVIDIA’s AI-at-scale simulation to see how {hardware} and deployment decisions have an effect on efficiency, effectivity and person expertise. To dive deeper on disaggregated serving and find out how Dynamo and NVIDIA GB200 NVL72 methods work collectively to spice up inference efficiency, learn this technical weblog.
For month-to-month updatesjoin the NVIDIA Assume SMART e-newsletter.

Amazon Basics Microfiber Cleaning Cloths, Ultra Absorbent, Lint Free, Streak Free, Non-Abrasive, Reusable and Washable, 16" x 12", Blue/White/Yellow, Pack of 24
$10.38 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AstroAI 27" Snow Brush and Ice Scrapers for Car Windshield, Detachable Snow Scrapers with Ergonomic Foam Grip for Cars, Trucks, SUVs (Heavy Duty ABS, PVC Brush, Orange)
$16.99 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
USANOOKS Microfiber Cleaning Cloth Grey - 12 Pcs (12.5"x12.5") - High Performance - 1200 Washes, Ultra Absorbent Microfiber Towel Weave Grime & Liquid for Streak-Free Mirror Shine - Car Washing Cloth
$7.98 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Mobil 1 Advanced Fuel Economy Full Synthetic Motor Oil 0W-20, 5 Quart
$26.99 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HOMEXCEL Microfiber Cleaning Cloth 12 Pack, 12.5 x 12.5 inch Microfiber Towels for Cars, Ultra Absorbent Washing Cloth, Lint Free Streak Free Cleaning Rags for Car, Kitchen, and Window (Grey)
$5.99 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
CERAKOTE® Ceramic Headlight Restoration Kit – Guaranteed To Last As Long As You Own Your Vehicle – Brings Headlights Back to Like New Condition - No Power Tools Required - 10 Wipe Kit
$17.95 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Valvoline High Mileage with MaxLife Technology SAE 5W-30 Synthetic Blend Motor Oil 5 QT
$26.99 (as of January 11, 2026 05:19 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)