
{kind=link}
AI is creating worth for everybody — from researchers in drug discovery to quantitative analysts navigating monetary market adjustments.
The sooner an AI system can produce tokensa unit of knowledge used to string collectively outputs, the better its impression. That’s why AI factories are key, offering essentially the most environment friendly path from “time to first token” to “time to first worth.”
AI factories are redefining the economics of contemporary infrastructure. They produce intelligence by remodeling knowledge into priceless outputs — whether or not tokens, predictions, pictures, proteins or different kinds — at huge scale.
They assist improve three key points of the AI journey — knowledge ingestion, mannequin coaching and high-volume inference. AI factories are being constructed to generate tokens sooner and extra precisely, utilizing three essential know-how stacks: AI fashions, accelerated computing infrastructure and enterprise-grade software program.
Learn on to learn the way AI factories are serving to enterprises and organizations around the globe convert essentially the most priceless digital commodity — knowledge — into income potential.
From Inference Economics to Worth Creation
Earlier than constructing an AI manufacturing unit, it’s necessary to know the economics of inference — methods to stability prices, power effectivity and an growing demand for AI.
Throughput refers back to the quantity of tokens {that a} mannequin can produce. Latency is the quantity of tokens that the mannequin can output in a particular period of time, which is commonly measured in time to first token — how lengthy it takes earlier than the primary output seems — and time per output token, or how briskly every extra token comes out. Goodput is a more recent metric, measuring how a lot helpful output a system can ship whereas hitting key latency targets.
Consumer expertise is essential for any software program utility, and the identical goes for AI factories. Excessive throughput means smarter AI, and decrease latency ensures well timed responses. When each of those measures are balanced correctly, AI factories can present partaking person experiences by shortly delivering useful outputs.
For instance, an AI-powered customer support agent that responds in half a second is way extra partaking and priceless than one which responds in 5 seconds, even when each in the end generate the identical variety of tokens within the reply.
Corporations can take the chance to put aggressive costs on their inference output, leading to extra income potential per token.
Measuring and visualizing this stability might be tough — which is the place the idea of a Pareto frontier is available in.
AI Manufacturing facility Output: The Worth of Environment friendly Tokens
The Pareto frontier, represented within the determine beneath, helps visualize essentially the most optimum methods to stability trade-offs between competing objectives — like sooner responses vs. serving extra customers concurrently — when deploying AI at scale.
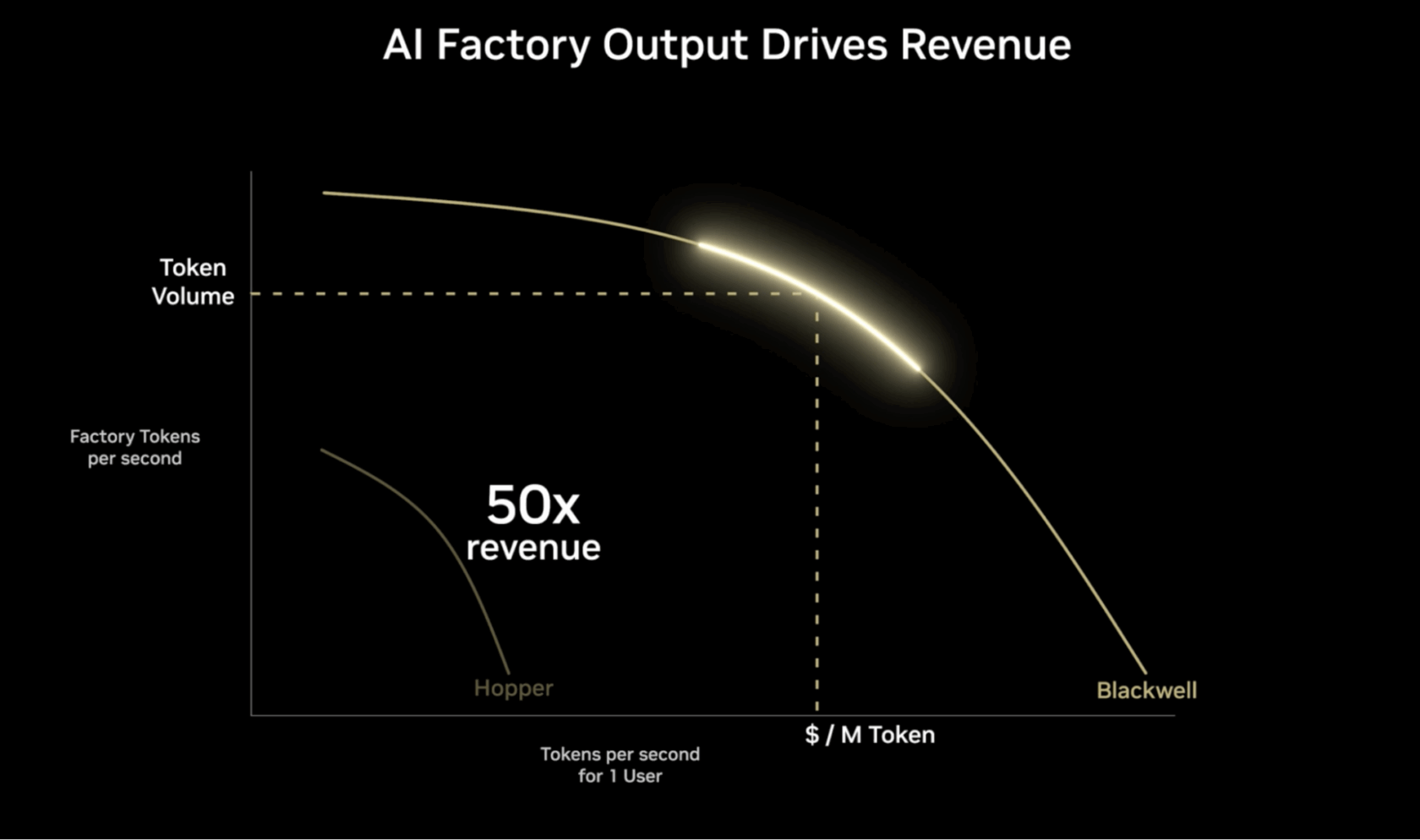
The vertical axis represents throughput effectivity, measured in tokens per second (TPS), for a given quantity of power used. The upper this quantity, the extra requests an AI manufacturing unit can deal with concurrently.
The horizontal axis represents the TPS for a single person, representing how lengthy it takes for a mannequin to offer a person the primary reply to a immediate. The upper the worth, the higher the anticipated person expertise. Decrease latency and sooner response instances are usually fascinating for interactive functions like chatbots and real-time evaluation instruments.
The Pareto frontier’s most worth — proven as the highest worth of the curve — represents the very best output for given units of working configurations. The aim is to search out the optimum stability between throughput and person expertise for various AI workloads and functions.
The very best AI factories use accelerated computing to extend tokens per watt — optimizing AI efficiency whereas dramatically growing power effectivity throughout AI factories and functions.

The animation above compares person expertise when operating on NVIDIA H100 GPUs configured to run at 32 tokens per second per person, versus NVIDIA B300 GPUs operating at 344 tokens per second per person. On the configured person expertise, Blackwell Extremely delivers over a 10x higher expertise and nearly 5x greater throughput, enabling as much as 50x greater income potential.
How an AI Manufacturing facility Works in Apply
An AI manufacturing unit is a system of parts that come collectively to show knowledge into intelligence. It doesn’t essentially take the type of a high-end, on-premises knowledge heart, however may very well be an AI-dedicated cloud or hybrid mannequin operating on accelerated compute infrastructure. Or it may very well be a telecom infrastructure that may each optimize the community and carry out inference on the edge.
Any devoted accelerated computing infrastructure paired with software program turning knowledge into intelligence by way of AI is, in follow, an AI manufacturing unit.
The parts embody accelerated computing, networking, software program, storage, techniques, and instruments and providers.
When an individual prompts an AI system, the complete stack of the AI manufacturing unit goes to work. The manufacturing unit tokenizes the immediate, turning knowledge into small items of which means — like fragments of pictures, sounds and phrases.
Every token is put by way of a GPU-powered AI mannequin, which performs compute-intensive reasoning on the AI mannequin to generate the very best response. Every GPU performs parallel processing — enabled by high-speed networking and interconnects — to crunch knowledge concurrently.
An AI manufacturing unit will run this course of for various prompts from customers throughout the globe. That is real-time inference, producing intelligence at industrial scale.
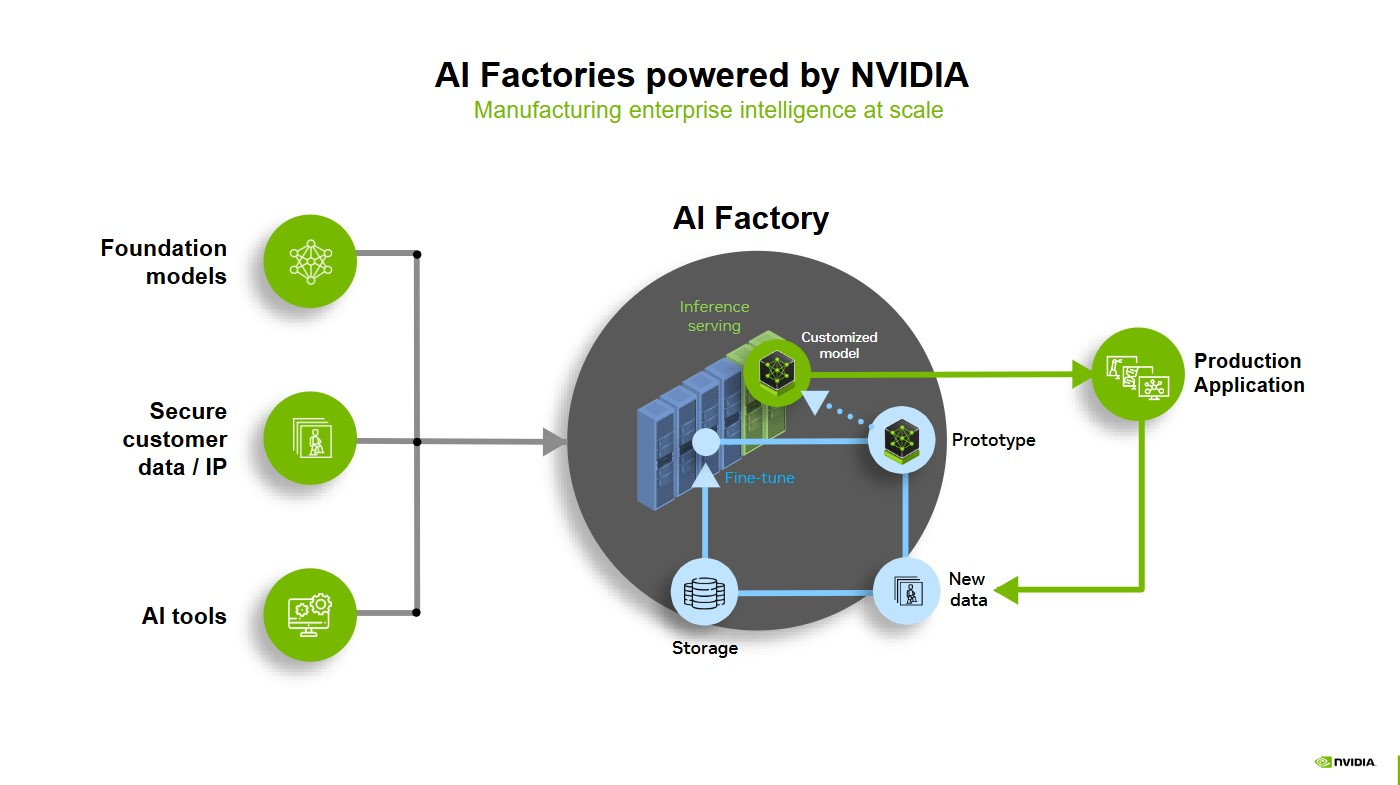
As a result of AI factories unify the complete AI lifecycle, this technique is constantly enhancing: inference is logged, edge circumstances are flagged for retraining and optimization loops tighten over time — all with out handbook intervention, an instance of goodput in motion.
Main international safety know-how firm Lockheed Martin has constructed its personal AI manufacturing unit to help numerous makes use of throughout its enterprise. By way of its Lockheed Martin AI Heart, the corporate centralized its generative AI workloads on the NVIDIA DGX SuperPOD to coach and customise AI fashions, use the complete energy of specialised infrastructure and scale back the overhead prices of cloud environments.
“With our on-premises AI manufacturing unit, we deal with tokenization, coaching and deployment in home,” mentioned Greg Forrest, director of AI foundations at Lockheed Martin. “Our DGX SuperPOD helps us course of over 1 billion tokens per week, enabling fine-tuning, retrieval-augmented era or inference on our massive language fashions. This resolution avoids the escalating prices and important limitations of charges based mostly on token utilization.”
NVIDIA Full-Stack Applied sciences for AI Manufacturing facility
An AI manufacturing unit transforms AI from a collection of remoted experiments right into a scalable, repeatable and dependable engine for innovation and enterprise worth.
NVIDIA gives all of the parts wanted to construct AI factories, together with accelerated computing, high-performance GPUs, high-bandwidth networking and optimized software program.
NVIDIA Blackwell GPUs, for instance, might be related by way of networking, liquid-cooled for power effectivity and orchestrated with AI software program.
The NVIDIA Dynamo open-source inference platform gives an working system for AI factories. It’s constructed to speed up and scale AI with most effectivity and minimal value. By intelligently routing, scheduling and optimizing inference requests, Dynamo ensures that each GPU cycle ensures full utilization, driving token manufacturing with peak efficiency.
NVIDIA Blackwell GB200 Nvl72 techniques and NVIDIA InfiniBand networking are tailor-made to maximise token throughput per watt, making the AI manufacturing unit extremely environment friendly from each whole throughput and low latency views.
By validating optimized, full-stack options, organizations can construct and keep cutting-edge AI techniques effectively. A full-stack AI manufacturing unit helps enterprises in reaching operational excellence, enabling them to harness AI’s potential sooner and with better confidence.
Study extra about how AI factories are redefining knowledge facilities and enabling the following period of AI.

AstroAI Tire Inflator Portable Air Compressor Air Pump for Car Tires-Car Accessories, 9.8Ft Cord-12V DC-Powered Auto Pump with Digital Pressure Gauge, Emergency LED Light for Bicycle, Balloons, Yellow
$27.17 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
All-Purpose Stainless Steel Shower Squeegee for Shower Glass Door with 2 Adhesive Hooks, Bathroom Cleaner Tool Household Window Mirror Squeegee , Cleaning Tile Wall, Car, 10 Inch Silver
$9.99 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
NOCO GENIUS1: 1A 6V/12V Smart Battery Charger – Automatic Maintainer, Trickle Charger & Desulfator with Overcharge Protection & Temperature Compensation – for Lead-Acid & Lithium Batteries
$29.95 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amazon Basics Microfiber Cleaning Cloths, Ultra Absorbent, Lint Free, Streak Free, Non-Abrasive, Reusable and Washable, 16" x 12", Blue/White/Yellow, Pack of 24
$9.59 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amooca Car Seat Headrest Hook 4 Pack Hanger Storage Organizer Universal for Handbag Purse Coat fit Universal Vehicle Car Black S Type
$6.99 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Mobil 1 Extended Performance High Mileage Full Synthetic Motor Oil 5W-30, 5 Quart
$29.97 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AUTOBOO 26" and 16" Windshield Wipers Blades (Pack Of 2),OEM Quality Premium All-Seasons Wiper blades,Stable and Quiet Armor wiper blades
$16.99 (as of February 28, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)