
{kind=link}
The NVIDIA Blackwell platform has been extensively adopted by main inference suppliers corresponding to Baseten, DeepInfra, Fireworks AI and Collectively AI to cut back value per token by as much as 10x. Now, the NVIDIA Blackwell Extremely platform is taking this momentum additional for agentic AI.
AI brokers and coding assistants are driving explosive development in software-programming-related AI queries: from 11% to about 50% final yr, based on OpenRouter’s State of Inference report. These purposes require low latency to take care of real-time responsiveness throughout multistep workflows and lengthy context when reasoning throughout whole codebases.
New SemiAnalysis InferenceX efficiency information exhibits that the mixture of NVIDIA’s software program optimizations and the next-generation NVIDIA Blackwell Extremely platform has delivered breakthrough advances on each fronts. NVIDIA GB300 NVL72 methods now ship as much as 50x increased throughput per megawatt, leading to 35x decrease value per token in contrast with the NVIDIA Hopper platform.
By innovating throughout chips, system structure and software program, NVIDIA’s excessive codesign accelerates efficiency throughout AI workloads — from agentic coding to interactive coding assistants — whereas driving down prices at scale.

GB300 NVL72 Delivers as much as 50x Higher Efficiency for Low-Latency Workloads
Latest evaluation from Signal65 exhibits that NVIDIA GB200 NVL72 with excessive {hardware} and software program codesign delivers greater than 10x extra tokens per watt, leading to one-tenth the fee per token in contrast with the NVIDIA Hopper platform. These large efficiency positive factors proceed to increase because the underlying stack improves.
Steady optimizations from the NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake and SGLang groups proceed to considerably enhance Blackwell NVL72 throughput for mixture-of-experts (MoE) inference throughout all latency targets. As an example, NVIDIA TensorRT-LLM library enhancements have delivered as much as 5x higher efficiency on GB200 for low-latency workloads in contrast with simply 4 months in the past.
- Larger-performance GPU kernels optimized for effectivity and low latency assist benefit from Blackwell’s immense compute capabilities and enhance throughput.
- NVIDIA NVLink Symmetric Reminiscence permits direct GPU-to-GPU reminiscence entry for extra environment friendly communication.
- Programmatic dependent launch minimizes idle time by launching the following kernel’s setup section earlier than the earlier one completes.
Constructing on these software program advances, GB300 NVL72 — which options the Blackwell Extremely GPU — pushes the throughput-per-megawatt frontier to 50x in contrast with the Hopper platform.
This efficiency achieve interprets into superior economics, with NVIDIA GB300 reducing prices in contrast with the Hopper platform throughout your entire latency spectrum. Probably the most dramatic discount happens at low latency, the place agentic purposes function: as much as 35x decrease value per million tokens in contrast with the Hopper platform.
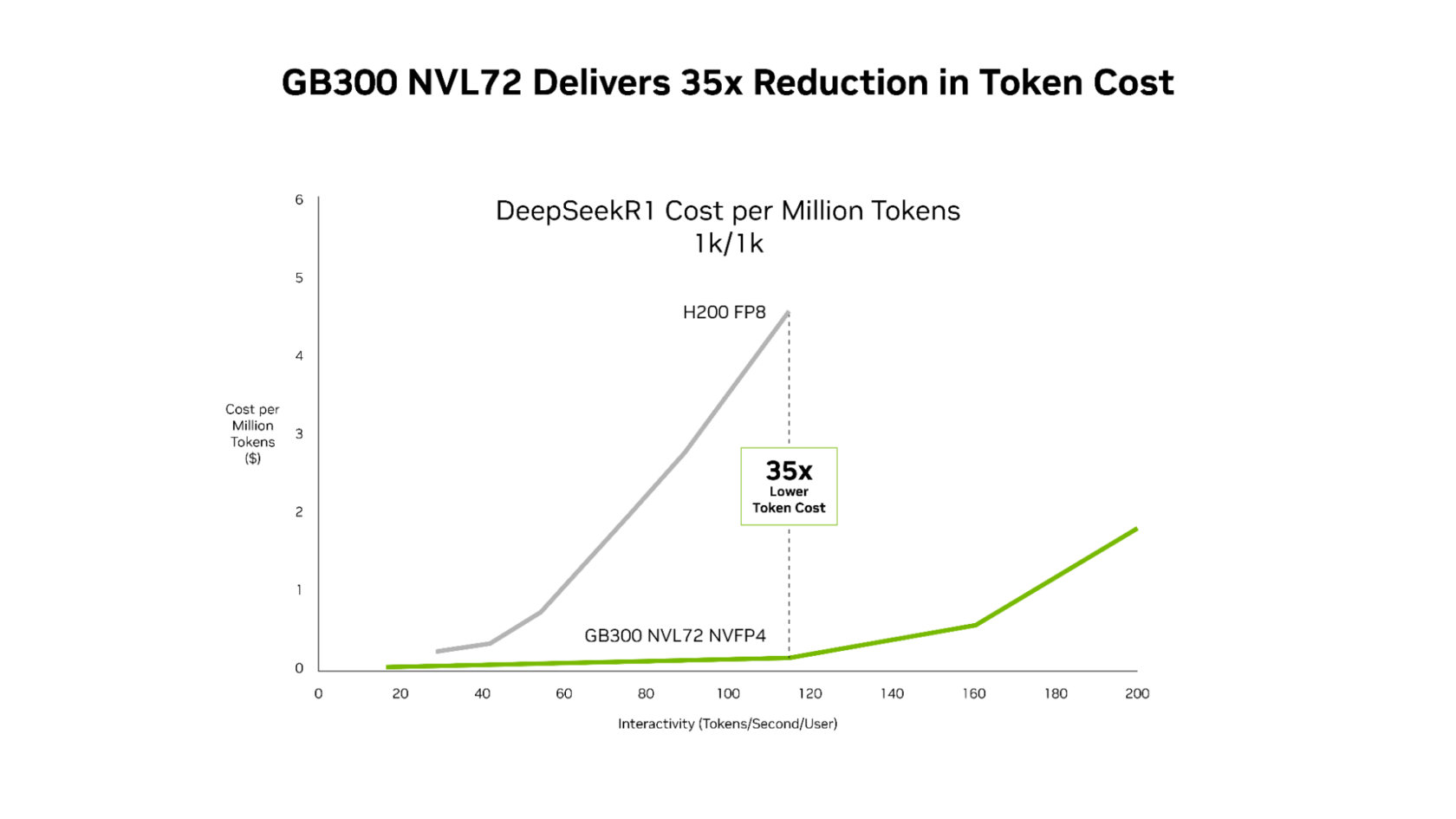
For agentic coding and interactive assistants workloads the place each millisecond compounds throughout multistep workflows, this mix of relentless software program optimization and next-generation {hardware} permits AI platforms to scale real-time interactive experiences to considerably extra customers.
GB300 NVL72 Delivers Superior Economics for Lengthy-Context Workloads
Whereas each GB200 NVL72 and GB300 NVL72 effectively ship ultralow latency, the distinct benefits of GB300 NVL72 change into most obvious in long-context situations. For workloads with 128,000-token inputs and eight,000-token outputs — corresponding to AI coding assistants reasoning throughout codebases — GB300 NVL72 delivers as much as 1.5x decrease value per token in contrast with GB200 NVL72.
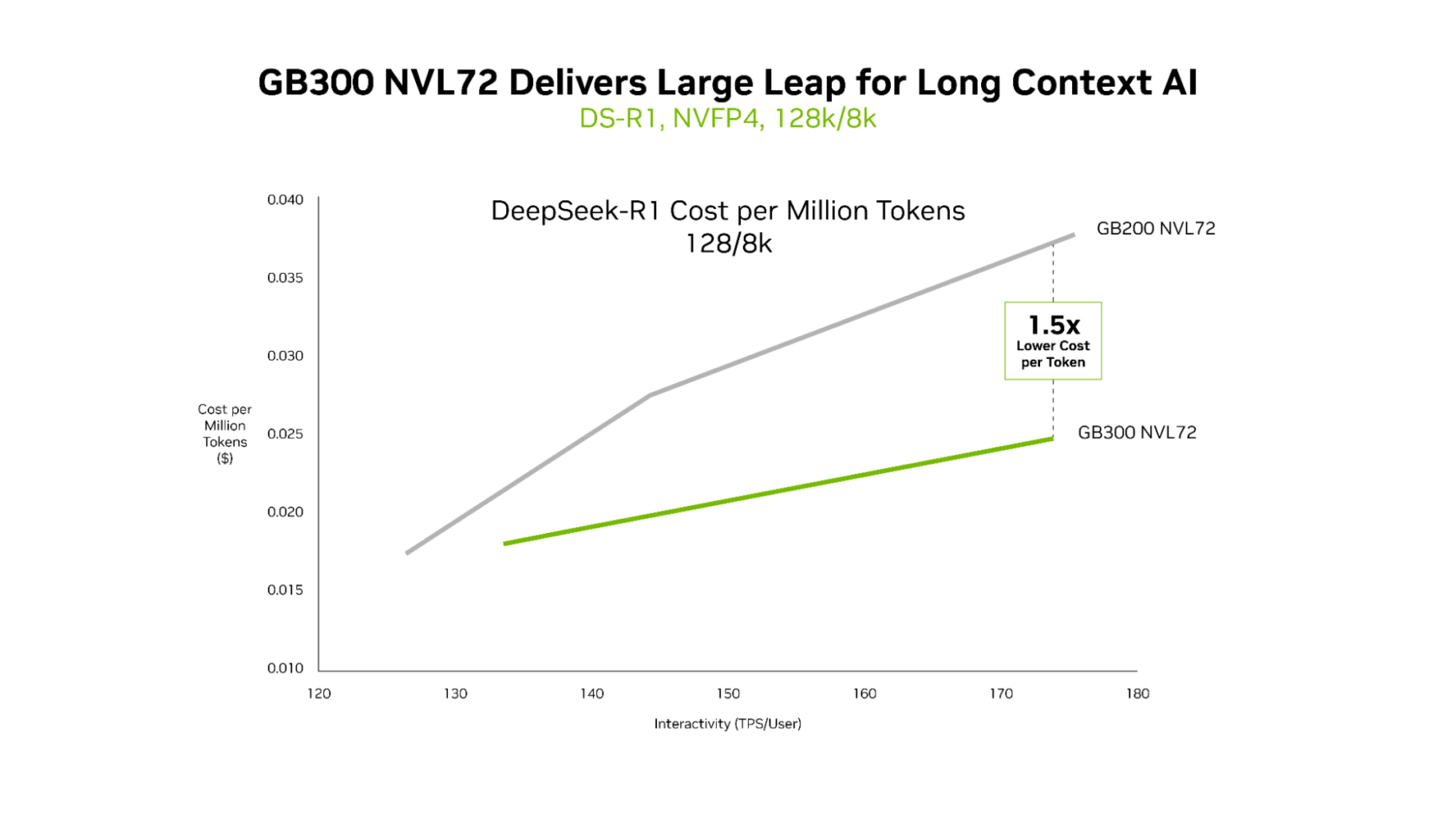
Context grows because the agent reads in additional of the code. This enables it to higher perceive the code base but additionally requires rather more compete. Blackwell Extremely has 1.5x increased NVFP4 compute efficiency and 2x sooner consideration processing, enabling the agent to effectively perceive whole code bases.
Infrastructure for Agentic AI
Main cloud suppliers and AI innovators have already deployed NVIDIA GB200 NVL72 at scale, and are additionally deploying GB300 NVL72 in manufacturing. Microsoft, CoreWeave and OCI are deploying GB300 NVL72 for low-latency and long-context use circumstances corresponding to agentic coding and coding assistants. By decreasing token prices, GB300 NVL72 permits a brand new class of purposes that may motive throughout large codebases in actual time.
“As inference strikes to the middle of AI manufacturing, long-context efficiency and token effectivity change into vital,” mentioned Chen Goldberg, senior vice chairman of engineering at CoreWeave. “Grace Blackwell NVL72 addresses that problem immediately, and CoreWeave’s AI cloud, together with CKS and SUNK, is designed to translate GB300 methods’ positive factors, constructing on the success of GB200, into predictable efficiency and value effectivity. The result’s higher token economics and extra usable inference for patrons working workloads at scale.”
NVIDIA Vera Rubin NVL72 to Deliver Subsequent-Technology Efficiency
With NVIDIA Blackwell methods deployed at scale, steady software program optimizations will maintain unlocking further efficiency and value enhancements throughout the put in base.
Wanting forward, the NVIDIA Rubin platform — which mixes six new chips to create one AI supercomputer — is ready to ship one other spherical of large efficiency leaps. For MoE inference, it delivers as much as 10x increased throughput per megawatt in contrast with Blackwell, translating into one-tenth the fee per million tokens. And for the following wave of frontier AI fashions, Rubin can prepare massive MoE fashions utilizing simply one-fourth the variety of GPUs in contrast with Blackwell.
Study extra in regards to the NVIDIA Rubin platform and the Vera Rubin NVL72 system.

All-Purpose Stainless Steel Shower Squeegee for Shower Glass Door with 2 Adhesive Hooks, Bathroom Cleaner Tool Household Window Mirror Squeegee , Cleaning Tile Wall, Car, 10 Inch Silver
$9.49 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AstroAI L7 Tire Inflator Portable Air Compressor Cordless Mini Bike Pump with Digital Dual Values Display, 150 PSI Car Tires Air Pump with LED Lights&Pressure Gauge for Auto, Motorcycles, Bikes, Balls
$19.99 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Valvoline High Mileage with MaxLife Technology SAE 5W-30 Synthetic Blend Motor Oil 5 QT
$19.97 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Amazon Basics Microfiber Cleaning Cloths, Ultra Absorbent, Lint Free, Streak Free, Non-Abrasive, Reusable and Washable, 16" x 12", Blue/White/Yellow, Pack of 24
$9.98 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Spearhead Odor Defense Breathe Easy AC & Heater Cabin Filter | Fits Various 2009-2025 Acura/Honda Like OEM | Up to 25% Longer Lasting w/Activated Carbon (BE-182)
$10.99 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Loctite Threadlocker Blue 242 - Removable Thread Lock Glue for Nuts, Bolts, & Fasteners, Medium Strength Screw Glue to Prevent Loosening & Corrosion - 6 ml, 1 Pack
$5.93 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Valvoline Advanced Full Synthetic SAE 0W-20 Motor Oil 5 QT
$26.97 (as of February 15, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)