
{kind=link}
The Sherox in lab analysis group on the College of California San Diego — on the forefront of pioneering AI mannequin innovation — lately obtained an NVIDIA DGX B200 system to raise their important work in massive language mannequin inference.
Many LLM inference platforms in manufacturing right now, corresponding to NVIDIA Dynamouse analysis ideas that originated within the Hao AI Lab, together with DistServe.
How Is Hao AI Lab Utilizing the DGX B200??

With the DGX B200 now totally accessible to the Hao AI Lab and broader UC San Diego neighborhood on the College of Computing, Info and Knowledge Sciences’ San Diego Supercomputer Middlethe analysis alternatives are boundless.
“DGX B200 is without doubt one of the strongest AI methods from NVIDIA to this point, which implies that its efficiency is among the many greatest on this planet,” stated Hao Zhang, assistant professor within the Hal?c?o?lu Knowledge Science Institute and division of pc science and engineering at UC San Diego. “It allows us to prototype and experiment a lot quicker than utilizing previous-generation {hardware}.”
Two Hao AI Lab tasks the DGX B200 is accelerating are FastVideo and the Lmgame benchmark.
FastVideo focuses on coaching a household of video technology fashions to supply a five-second video based mostly on a given textual content immediate — in simply 5 seconds.
The analysis part of FastVideo faucets into NVIDIA H200 GPUs along with the DGX B200 system.
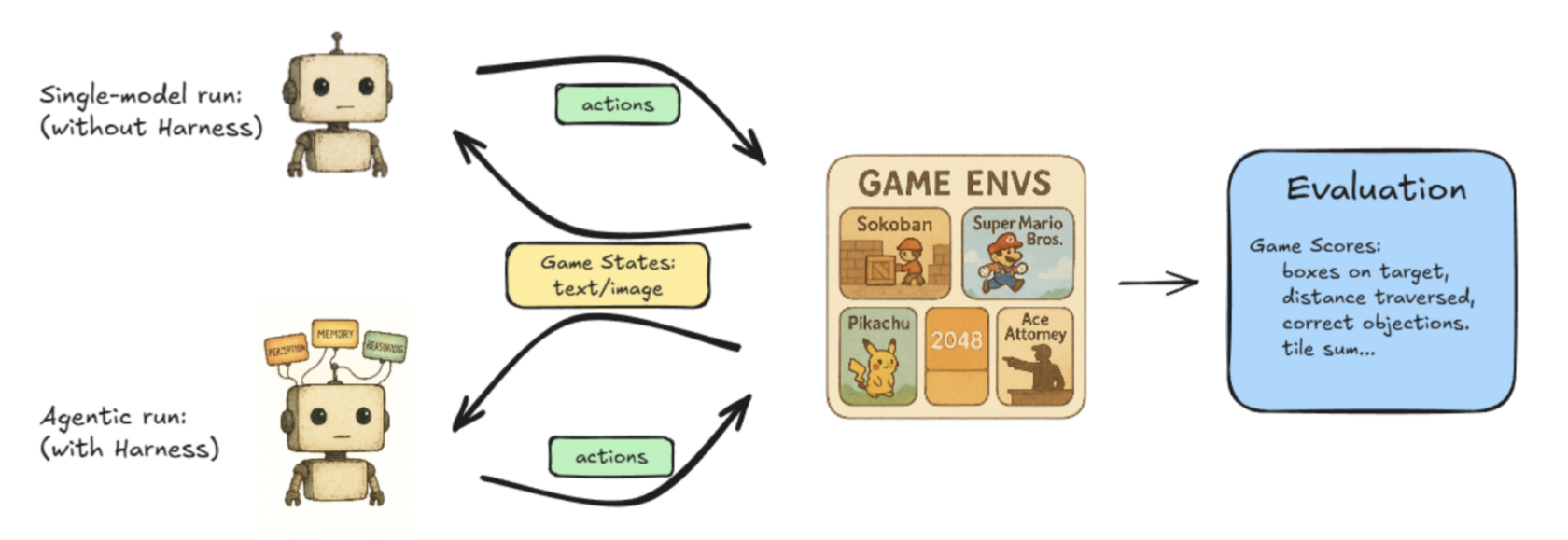
Lmgame-bench is a benchmarking suite that places LLMs to the take a look at utilizing fashionable on-line video games together with Tetris and Tremendous Mario Bros. Customers can take a look at one mannequin at a time or put two fashions up in opposition to one another to measure their efficiency.
Different ongoing tasks at Hao AI Labs discover new methods to realize low-latency LLM serving, pushing massive language fashions towards real-time responsiveness.
“Our present analysis makes use of the DGX B200 to discover the subsequent frontier of low-latency LLM-serving on the superior {hardware} specs the system provides us,” stated Junda Chen, a doctoral candidate in pc science at UC San Diego.
How DistServe Influenced Disaggregated Serving
Disaggregated inference is a means to make sure large-scale LLM-serving engines can obtain the optimum combination system throughput whereas sustaining acceptably low latency for person requests.
The advantage of disaggregated inference lies in optimizing what DistServe calls “goodput” as a substitute of “throughput” within the LLM-serving engine.
Right here’s the distinction:
Throughput is measured by the variety of tokens per second that the complete system can generate. Larger throughput means decrease price to generate every token to serve the person. For a very long time, throughput was the one metric utilized by LLM-serving engines to measure their efficiency in opposition to each other.
Whereas throughput measures the mixture efficiency of the system, it doesn’t straight correlate to the latency {that a} person perceives. If a person calls for decrease latency to generate the tokens, the system has to sacrifice throughput.
This pure trade-off between throughput and latency is what led the DistServe group to suggest a brand new metric, “goodput”: the measure of throughput whereas satisfying the user-specified latency aims, often referred to as service-level aims. In different phrases, goodput represents the general well being of a system whereas satisfying person expertise.
DistServe exhibits that goodput is a a lot better metric for LLM-serving methods, because it components in each price and repair high quality. Goodput results in optimum effectivity and ideally suited output from a mannequin.
How Can Builders Obtain Optimum Goodput?
When a person makes a request in an LLM system, the system takes the person enter and generates the primary token, often called prefill. Then, the system creates quite a few output tokens, one after one other, predicting every token’s future habits based mostly on previous requests’ outcomes. This course of is named decode.
Prefill and decode have traditionally run on the identical GPU, however the researchers behind DistServe discovered that splitting them onto totally different GPUs maximizes goodput.
“Beforehand, for those who put these two jobs on a GPU, they might compete with one another for assets, which might make it sluggish from a person perspective,” Chen stated. “Now, if I cut up the roles onto two totally different units of GPUs — one doing prefill, which is compute intensive, and the opposite doing decode, which is extra reminiscence intensive — we will essentially remove the interference between the 2 jobs, making each jobs run quicker.
This course of is named prefill/decode disaggregation, or separating the prefill from decode to get higher goodput.
Rising goodput and utilizing the disaggregated inference technique allows the continual scaling of workloads with out compromising on low-latency or high-quality mannequin responses.
NVIDIA Dynamo — an open-source framework designed to speed up and scale generative AI fashions on the highest effectivity ranges with the bottom price — allows scaling disaggregated inference.
Along with these tasks, cross-departmental collaborations, corresponding to in healthcare and biology, are underway at UC San Diego to additional optimize an array of analysis tasks utilizing the NVIDIA DGX B200, as researchers proceed exploring how AI platforms can speed up innovation.
Be taught extra concerning the NVIDIA DGX B200 system.

All-Purpose Stainless Steel Shower Squeegee for Shower Glass Door with 2 Adhesive Hooks, Bathroom Cleaner Tool Household Window Mirror Squeegee , Cleaning Tile Wall, Car, 10 Inch Silver
$9.49 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Drift Car Air Freshener - The Original Wood Air Freshener - Car Odor Eliminator - Long Lasting Scent - Auto Accessories - Metal Clip - Essential Oils - Clean Ingredients - Teak Scent Starter Kit
$12.95 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
25" 22" 15" Windshield Wiper Blades Replacement for VW Volkswagen Tiguan 2018 2019 2020 2021 2022 2023 2024 2025 Premium All Weather Front Rear Wipers Set - OEM Quality (Pack of 3)
$21.99 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Valvoline Advanced Full Synthetic SAE 0W-20 Motor Oil 5 QT
$26.97 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
HOMEXCEL Microfiber Cleaning Cloth 12 Pack, 12.5 x 12.5 inch Microfiber Towels for Cars, Ultra Absorbent Washing Cloth, Lint Free Streak Free Cleaning Rags for Car, Kitchen, and Window (Grey)
$6.98 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
Spearhead Odor Defense Breathe Easy AC & Heater Cabin Filter | Fits Various 2009-2025 Acura/Honda Like OEM | Up to 25% Longer Lasting w/Activated Carbon (BE-182)
$11.99 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
AUTOBOO 26" and 16" Windshield Wipers Blades (Pack Of 2),OEM Quality Premium All-Seasons Wiper blades,Stable and Quiet Armor wiper blades
$16.99 (as of February 20, 2026 23:22 GMT -08:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)